目录
- 感想
- 强化学习——原理
- 1:马尔科夫决策过程(MDP)
- 2:已知环境参数 | 动态规划
- 2.1 价值迭代
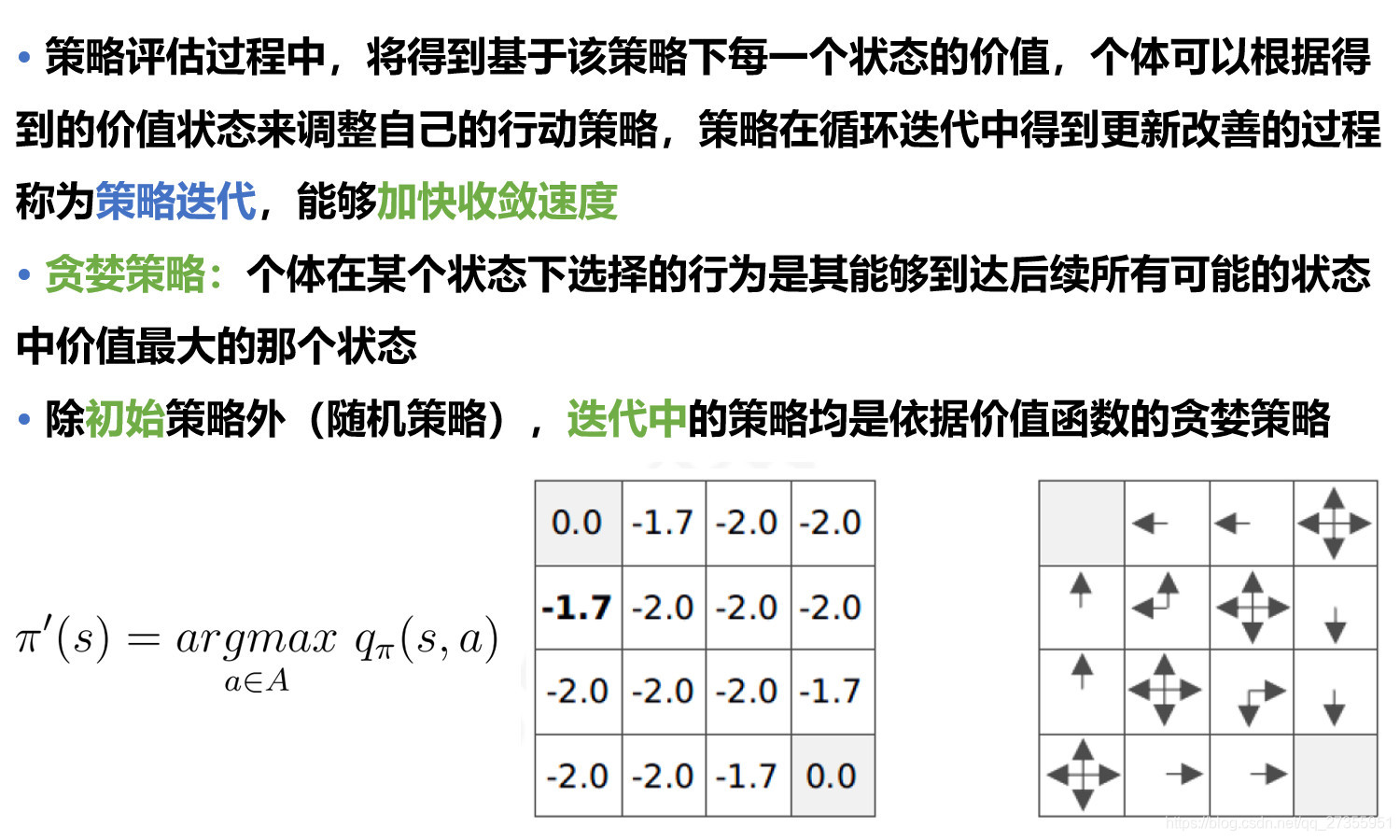
- 2.2 策略迭代
- 3:未知环境参数:
- 3.1 :不构建环境模型
- 3.1.1:状态有限、行为有限 | Q-Learning
- 3.1.2:状态无限、行为有限 | DQN
- 3.1.3:状态无限、行为无限 | DDPG
- 3.2:构建环境模型
- 3.2.1:基于模型的思考+直接学习 | Dyna-Q
- 3.2.2:基于模型的搜索 | MCTS
- 小结
- 参考资料
感想
在网上找到的学习资料《强化学习入门——从原理到实践》by叶强【1】,个人觉得写得很好,每一章都是有联系的,逐步深入,慢慢读下来,基本都能明白,推荐大家细读!
第一遍还是摘抄一些重点的知识点,并根据自己的理解再做一定的加工整理。
强化学习——原理
该学习资料的内容基本就是按下图从左至右,从上到下的顺序展开的,内容比较多,但其实各部分之间都是有联系的。
· 强化学习并不是某一种特定的算法,而是一类算法的统称
· 训练方法:强化能够获得较高奖励的策略
· 不基于模型的算法不会对环境进行建模,直接根据交互数据来迭代算法
1:马尔科夫决策过程(MDP)
· 几乎所有的强化学习问题都可以被认为或可以被转化为马尔科夫决策过程(Markov Decision Process, MDP)
· 马尔科夫:俄国数学家,主要研究领域为概率和统计,开创了随机过程领域【2】
· 主要内容:
马尔科夫过程:⟨ S, P ⟩
马尔科夫奖励过程: ⟨ S, P,R,γ ⟩
马尔科夫决策过程: ⟨ S, A,P ,R,γ ⟩
S :有限数量的状态集,P :状态转移概率矩阵, R :奖励函数,γ:衰减因子,A :有限行为集
①马尔科夫过程:
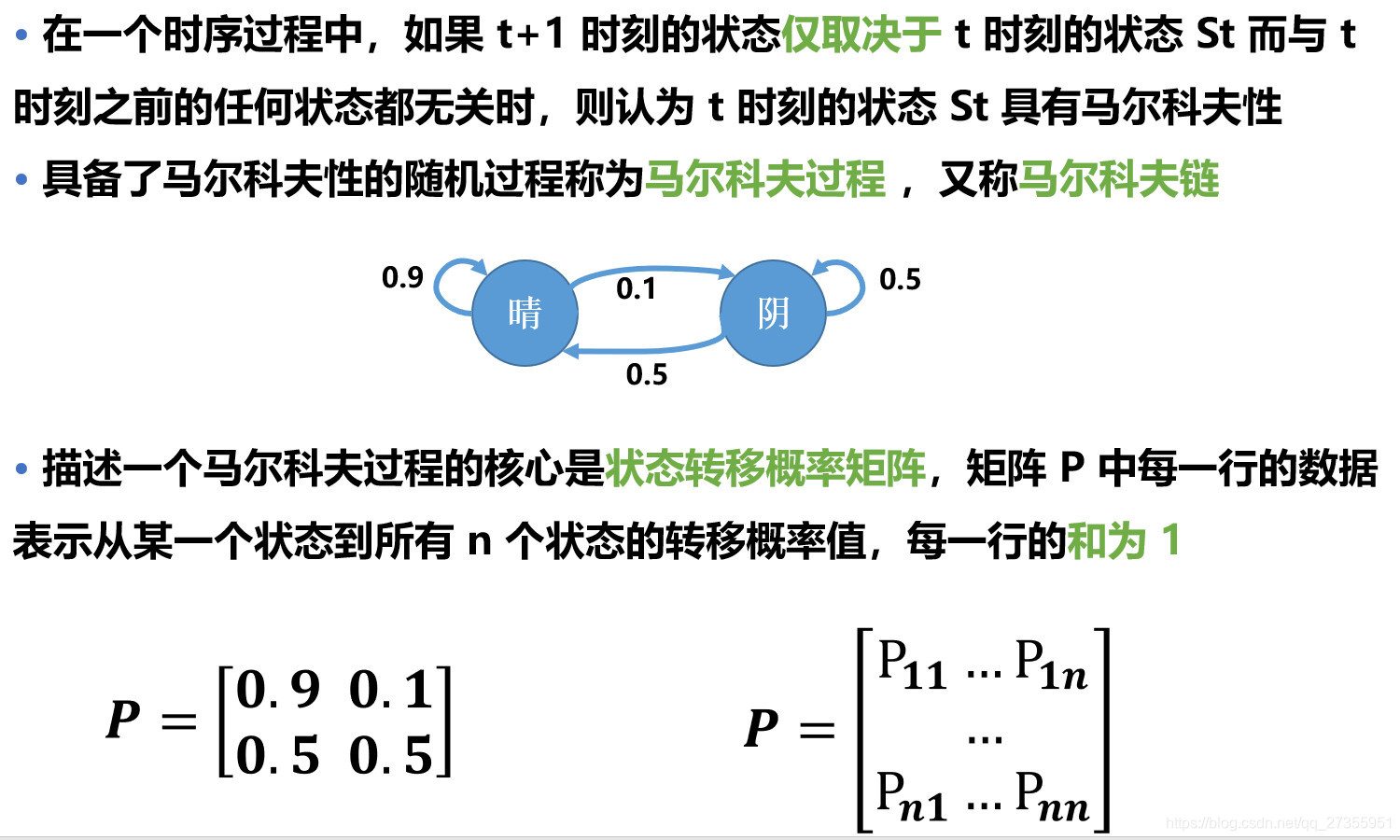
②马尔科夫奖励过程

③马尔科夫决策过程


2:已知环境参数 | 动态规划
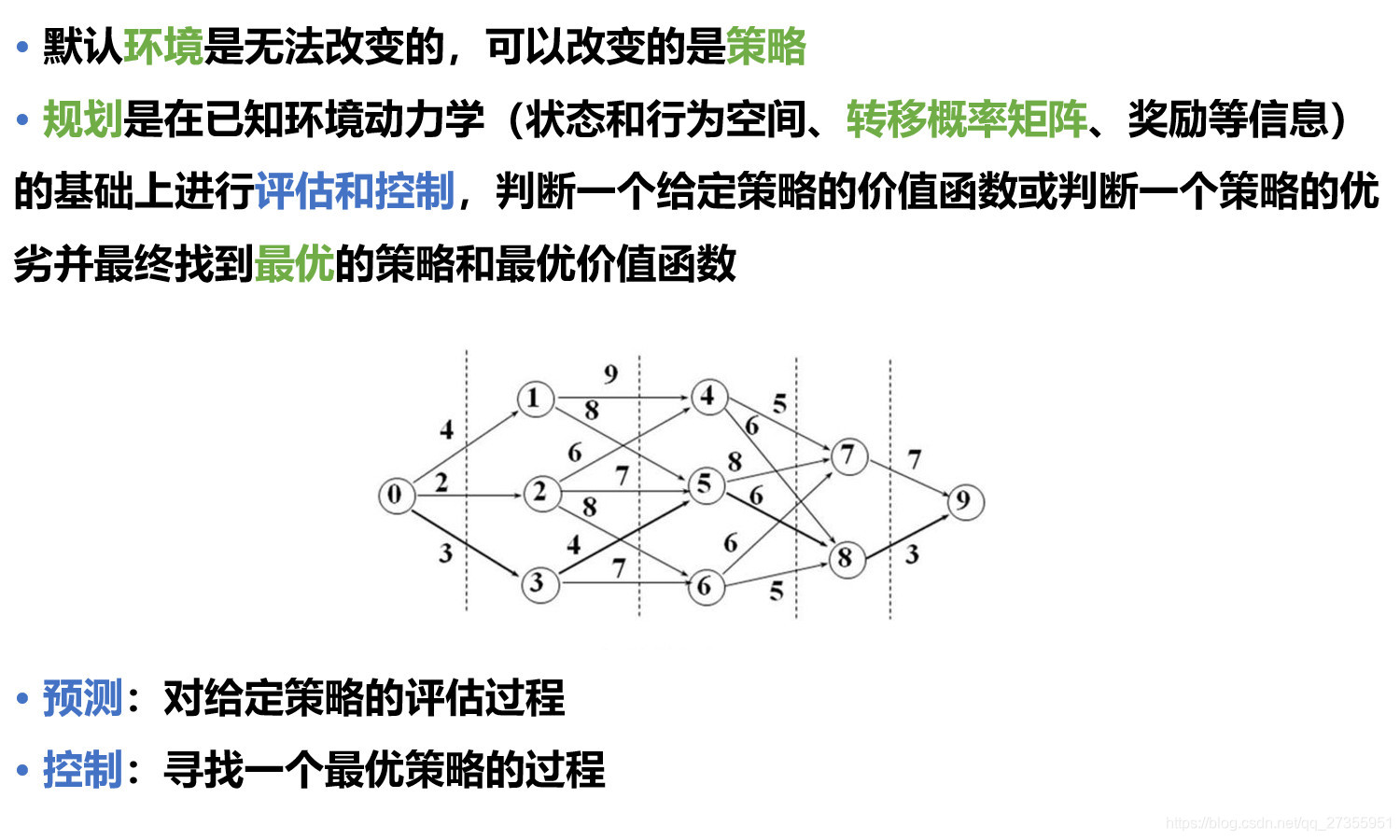
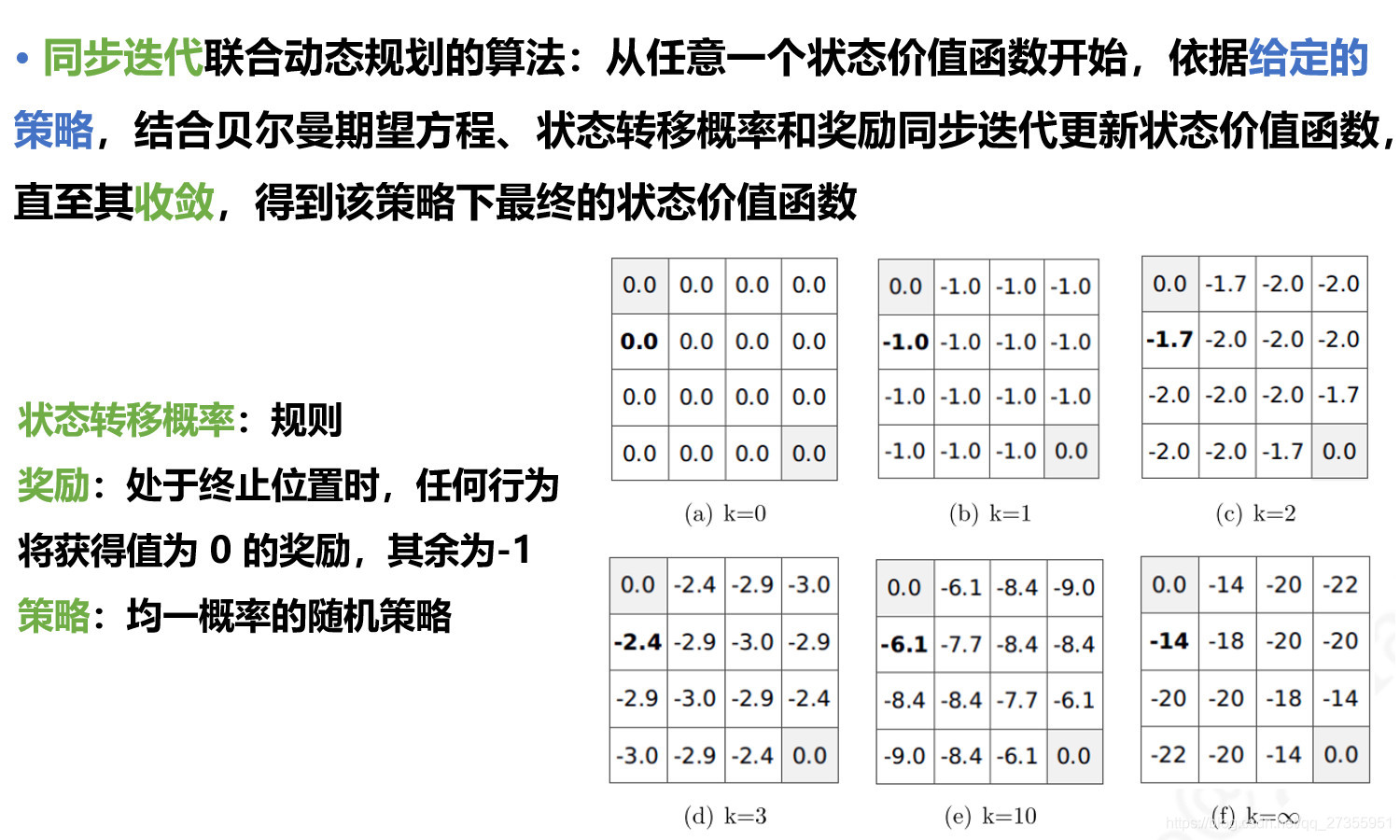
2.1 价值迭代

2.2 策略迭代
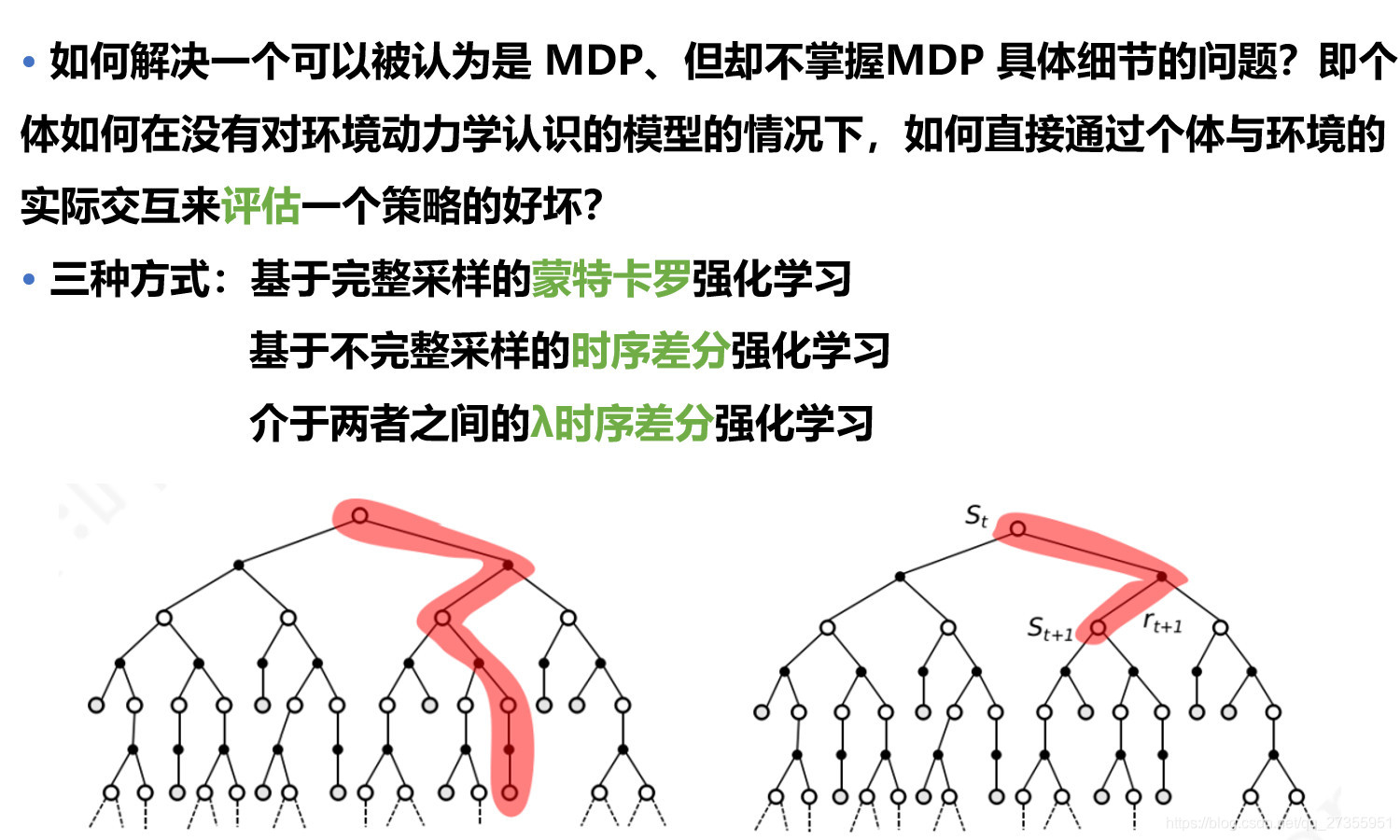
3:未知环境参数:
3.1 :不构建环境模型
未知状态转移矩阵,则需要采样
①蒙特卡洛采样:

②时序差分采样

③n步时序差分采样


3.1.1:状态有限、行为有限 | Q-Learning
①现时策略:MC控制
②现时策略:Sarsa、Sarsa(λ)控制


③借鉴策略:Q-Learning

小结:

3.1.2:状态无限、行为有限 | DQN


3.1.3:状态无限、行为无限 | DDPG



3.2:构建环境模型

3.2.1:基于模型的思考+直接学习 | Dyna-Q

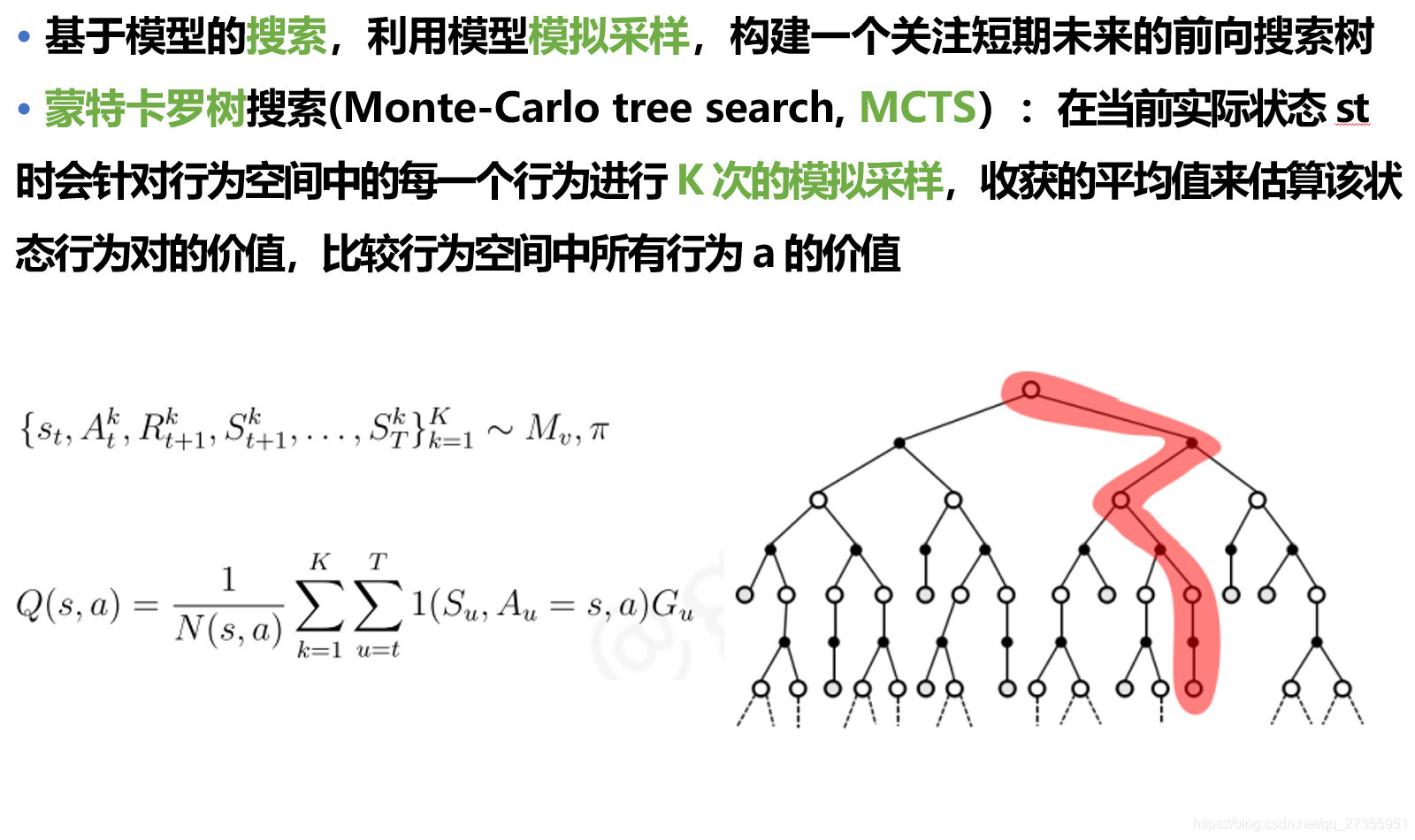
3.2.2:基于模型的搜索 | MCTS
小结
第一遍学习,能够大概明白机器学习的思想,感觉最主要的是动态规划那边的处理思路,然后将一些已知条件变为未知、离散变为连续,就衍生出了各种不同的算法。下一遍就要看代码调试了,应该会有更深入的理解吧!
参考资料
【1】https://github.com/qqiang00/reinforce
【2】https://baike.baidu.com/item/%E5%AE%89%E5%BE%B7%E9%9B%B7%C2%B7%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB/10445098?fromtitle=%E9%A9%AC%E5%B0%94%E5%8F%AF%E5%A4%AB&fromid=2774684